Distributed Parallel Recursive File Decompression Sample - Windows HPC SOA Model
Introduction
This is the second of the three part series of article and sample duo describing the three main approaches to write parallel applications for Windows HPC Server.
We’re proposing to solve a simple parallel problem – recursive file decompressing - using three different approaches; this should help to understand and contrast the three different models:
Using Windows HPC Scheduler API
Using Service Oriented Architecture HPC model
Traditional MPI based approach
It’s recommended that you read the first article (link) to better understand what we’re trying to accomplish. If you’re new to Windows HPC and in particular to SOA application model approach proposed by Windows HPC, then I recommend you to take at look at this article: SOA Applications, Infrastructure and Management with Windows® HPC 2008 R2.
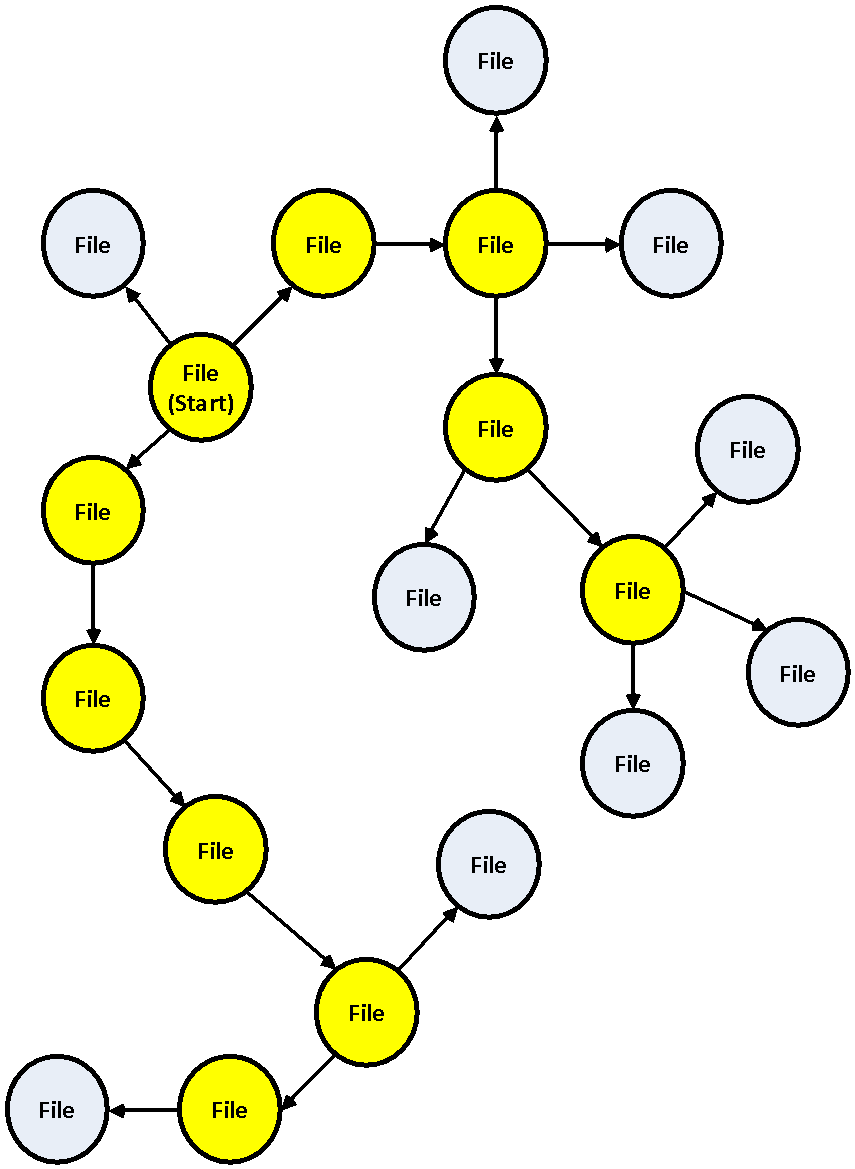
As previously described, the recursive file decompressing problem maps naturally to the conceptual hub/spoke model . The diagram bellow depicts this model in the context of file decompression: each hub (yellow) represents a file in compressed format. When a file is decompressed it generates one or more files; eventually some of the resulting files might be in compressed form and we start all over.
The initial solution to this problem took advantage of the Windows HPC scheduler API to enable the parallel execution of as many decompression tasks as possible given the required or available computing capacity.
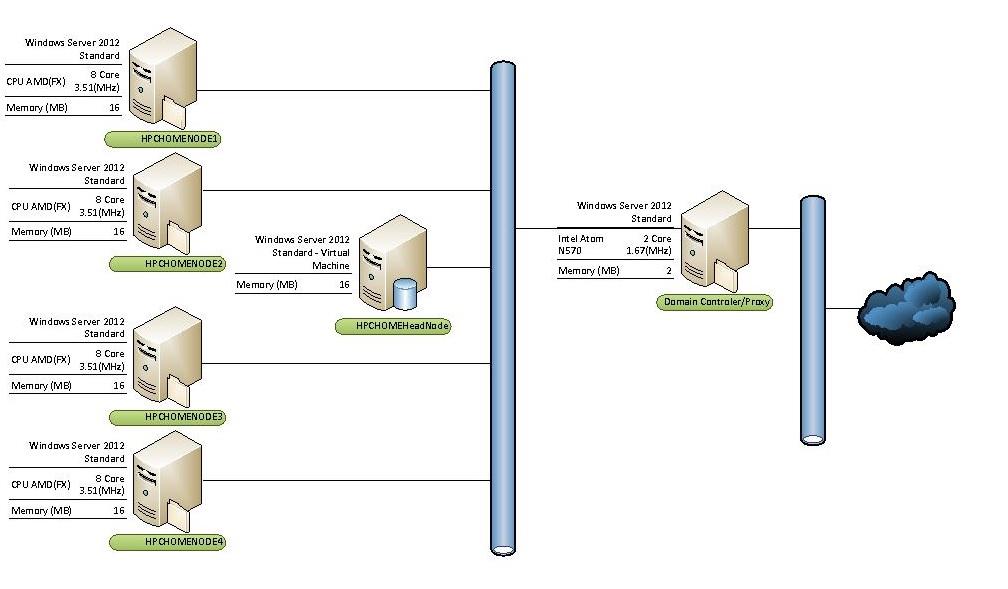
In my Home HPC cluster I have 5 machines with 34 cores available; in this small cluster, using the core allocation model we can have at any single moment a maximum of 36 parallel tasks being executed.
The initial programming approach to solve this problem is the most straightforward because it relegate all the expensive data extensive use of the scheduler API to allocate each decompressing task to cores as it becomes available. To better understand how this parallelization takes place, Let consider the initial set of files we used for our benchmarks:
Insert the List of files here …..
After we run our sample program targeting this initial list of 16 files the result is: files, size.
As we look into Windows HPC Server Scheduler – screenshot below - we can see that 67 task were created as the result of running our program – each task launches an executable – our sample program. If we used the conceptual hub/spoke model diagram above we would end up with 67 yellow circles (hubs) and XXXX white circles.
The initial program relies on scheduler to start a task (process) every time our program finds a file that needs to be decompressed. The logic of the program is quite simple because we don’t have to worry about communicating of other process when we find a new file. The information about a new file to be decompressed is sent to the scheduler and the scheduler will take care of creating a new process to decompress that particular file.
Applying the new model
The most direct way to implement our initial sample using SOA model would be converting our program into a WCF service. This way instead of the scheduler launching executables for every required decompression, we would have the scheduler calling a WCF service instead. What I don’t like about this approach is the fact that the client making the initial request would be responsible to receive the return value from the service calls and then make make additional service calls to decompress additional files. In this scenario the client may become a bottleneck unless you want to create a somehow complex parallel asynchronous call back algorithm to be able to handle response/ requests in parallel. With this in mind I decided to make a small but significant change in program logic. We’re going to introduce some minimal inter-process communication to allow for services to communicate to other services running in parallel about the availability of a new file in need of decompression.
In ordert to allow for the WCF web services to communicate with each other we’re going to use a cache solution: Window AppFabric Cache. It’s out of the scope of this article to discuss the AppFabric cache. A good reference to learn about about this technology and in particular in the context of Windows HPC SOA applications, I recommend this article - Use AppFabric Caching for Common Data in Windows HPC Server 2008 R2.
I’m borrowing a diagram from this article to help demonstrate how the solution will look like:
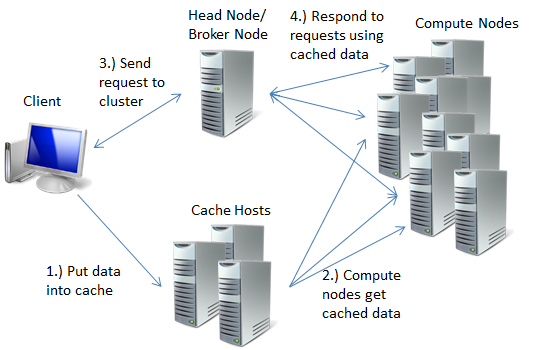
The logic for our SOA implementation is similar to the initial program except that this time we’re going to store send the information about a new file to be decompressed to the cache. A main loop inside the WCF service will look like this:
1 – check the cache for a file to be decompressed
2 –try to update the cache to inform that the file has been taken for decompression
We don’t want more the one process decompressing the same file
3- if we succeed we launch a local 7zip to decompress the file
4-after the file decompression finishes we call walkdirectory tree to to browse the resulting files from the previous decompression to check for additional files to be decompressed
For every file we find that needs to be decompressed we update the cache with the path to this files. This way other WCF services running in any core/machine can start working to decompress this file.
This logic repeats until there are no more files to be decompressed.
The
No comments:
Post a Comment