Distributed Parallel Recursive File Decompression - Windows HPC Scheduler API version
This is the first part of a series of three samples I'm writing to exercise the main approaches to writing a parallel program using Windows HPC Server 2012. To refresh our memories here are the three approaches I'm going to cover:
❖ Using the Windows HPC Scheduler API - let's put the Windows HPC scheduler under some stress.
❖ Using Service Oriented Architecture HPC - I expect to see the best performance of the three approaches; we'll see...
❖ Traditional MPI based approach - you gotta have the classic represented!
Let's start by describing what we're trying to demonstrate with this sample.
Problem
You have a large number of compressed files that need to decompressed. After you decompress a file the result is one or a number of additional files. For some scenarios you may also need to go over the resulting decompressed files to check if there aren't any additional files that are still compressed. As a result we want to keep checking recursively until there's no more files in a compressed form.
You also want to serve multiple users simultaneously, distribute your processing load properly using the existing resources, and provide a scalable model for future growth.
Context
We want the file decompression to run in parallel and also to properly scale to multiple computing capacity as it becomes available. We want the solution to scale at different levels:
- scale-up: take advantage of multi-core CPUs while running on a single computer (node)
- scale-out: take advantage of clusters with multiple computers (nodes )
- cloud scale: augment on premises cluster processing capacity by adding compute nodes on the cloud (hybrid) or running the solution entirely on the cloud.
In order to achieve all the above, we 're going to leverage as much as possible any available packaged solution in detriment of any custom implementation. After all, this is just a simple sample program and we have very limited programming resources.
Solution
To tackle the problem at hand we're going to rely on Windows HPC scheduler API to implement parallelism in our solution. The reason to start with this approach is the fact that it provides a very simple model to address what is known as embarrassing parallel type of problems – a parallel algorithm in which there's no dependencies between tasks. As you might have guessed the problem we are trying to solve - parallel decompression - is a great example of this type of problem: the decompression of a file has no dependency on what's going on as other files are decompressed.
Microsoft Windows HPC Server offers a highly scalable solution to address the demand of high parallel type of problems. It offers a rich programming interface that allows the implementation of parallel programs. We're going to leverage the Window HPC scheduler API to write a C# program that will allow for the parallel execution of multiple decompression tasks on a Windows HPC Server cluster.
Before we run into any confusion let me set things straight here: I'm not going to write the decompression algorithm per se; for this we're going to rely on a well know solution: 7Zip (http://www.7-zip.org/)
In summary what we are proposing here is the execution of several 7Zip tasks in parallel, distributed among cores (scale-up), nodes (scale-out), both on-premise, cloud or hybrid.
As we're going to see the initial implementation is quite simple and the aforementioned goals don't require any additional coding to implement since the magic is provided by the underline infrastructure of Windows HPC Server 2012.
The Microsoft Windows HPC Server offers a highly scalable solution to address the requirements of developers trying to solve large computing problems that require the execution of parallel algorithms.
From a conceptual perspective the solution is loosely based on the hub/spoke model as depicted below:
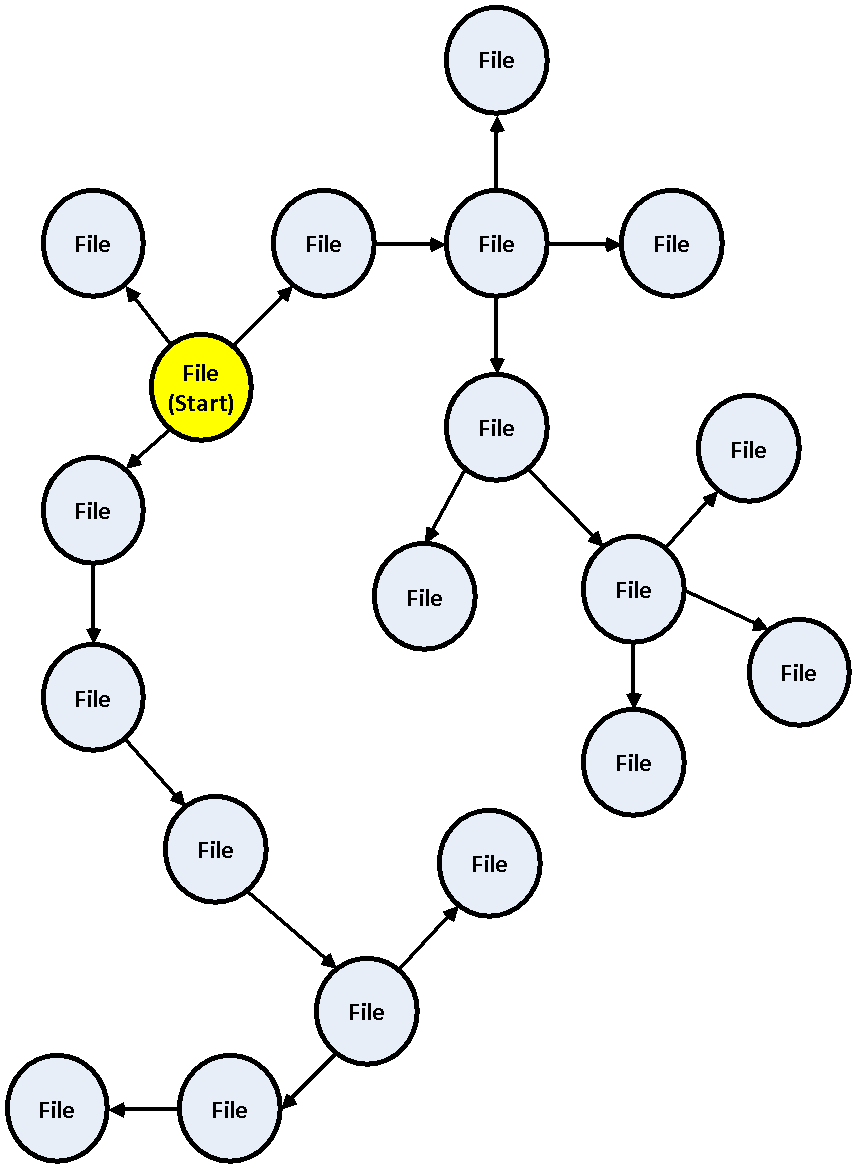
The file decompression problem offers an opportunity to apply this model as the number of tasks varies dynamically as the program executes.
Code
The C# program available here implements a simple logic that can be summarized by these simple steps:
validate command line parameters
check for a valid file or directory to decompress
connect to hpc scheduler
create a job with the amount of Cores as specified by the command line parameter:
-NumCores
Browse list of files pointed by the command line parameter:
-TargetDir
for each file check if it is a file that can be decompressed
True: create a new Task for this job passing the file to be decompressed - we're actually calling the very same program that in turn will execute the same logic.
False: Check the next file
Running the Program
This is the command line to execute the program:
C:\Program Files\FileExplosion\FileExplosion.exe" -ClusterName HPCHOME -TargetDir \\HPCHOMENode05\d$\decompression -NumCores 16 -TargetFile "none"
As you execute the program at the command line it connects to the Windows HPC cluster defined by:
-ClusterName HPCHOME
and creates a Job with the amount of resources as specified by: -NumCores 16.
Next it creates one task inside this job for each compressed file it finds at the directory pointed by the command line argument:
-TargetDir \\HPCHOMENode05\d$\decompression
The scheduler will run as many parallel tasks as the number of cores specified; as you might have guessed if you specify a single core there will be no parallelism at all. Cores may span one or more machines. In our 8 cores per Node (machine) cluster if we specify more than 8 cores for a job we end up with tasks spanning multiple machines. Actually, the Windows HPC Scheduler will take care of allocating the resources to satisfy your request (number of cores) no matter how many cores are available on any particular node. Because of the scheduler infra-structure you don't need to worry about how many machines will be needed to satisfy your request or even where they are located: they can be on your local cluster, on the cloud, or both. Like I mentioned at beginning of this post, the solution will gracefully scale up, scale-out, and cloud scale.
Because we leverage file paths using UNC we can easily run the tasks from multiple cores/machines without any additional logic in our program. Yes, disk becomes a bottleneck with high volume of calls. In a scenario were high volumes are expected you want to come up with a pattern to segregate read/write operations. Writing the resulting files from a decompressing task to the local disk of the machine where the task is running might be a good idea. In this case you would need additional logic to collect the files that will be scatted throughout the machines that were allocated to run the tasks.
After the initial command line program ends, you may want to launch the Windows HPC Job Manager to check all the tasks created to complete the decompression; possibly new tasks are created as new files are found that need to be decompressed. This logic repeats until no more compressed files are found. A task is actually the very same initial program that we ran at the command line. This task will run in one of the cores (Nodes) of our cluster as the scheduler initially allocated and as they become available.
This screen show a job as it it's managed by the Windows HPC Scheduler after we start our initial program at the command line.
Initial Benchmarks:
Sample compressed files used (those are files are public files available on the internet):

16 Files for a total of 256MB compressed after decompressing resulting in 3294 files, 394 folders 942MB
I’m compiling results for additional benchmarks and will share soon.
Conclusion
By using the simple yet rich programming model offered by the Windows HPC scheduler we were able to create this sample program that serves as an example on how to solve parallel problems that fit the embarrassing parallel category - no dependency between tasks. By using the Windows HPC Scheduler we delegate the responsibility to check for available resources, launch the program, and monitor the execution of the processes all to the Windows HPC scheduler infra-structure; that way our program logic had to concentrate only on solving the decompressing (actually done by 7zip) delegating all the parallelism plumbing to Windows HPC.
Even if you consider this sample to be a good way to demonstrate the basics to implement a parallel solution it's not without some important limitations that impact performance. Because we choose not to have any communications between programs, the final implementation yielded a very large number of tasks that needs to be managed by the scheduler. As I mentioned in a previous post to this blog, one of the objectives of this sample was to put the schedule under some stress. There's no doubt we achieved this objective. In one of the tests the number of tasks created to unzip XX files was XXX. The problem with creating that many tasks to launch processes is that they're very expensive from an Operating System perspective.
If you look at the average processing time for each task - as show below for a sample execution of our program - you'll notice that most of the time the decompressing finishes very quick. Frequently, the time it takes to allocate resources and launch the task is bigger than the time it takes to complete it. Unless you have processes that will take some time to complete the computation, launching a single process for each slice of data – files in our sample - might not be a good approach.
As long as you understand the implications of creating lots process that complete in a very short window of time you can appropriately make use of this approach to implement your solution so you can optimize the use of the scheduler.
WHAT'S NEXT
Because of the implications and limitations of the initial implementation, we're going to propose the use of a new approach to solve this problem using what Windows HPC Server call: Service Oriented Applications HPC solutions. In this model we're going to implement our logic in a service DLL instead of using EXE. The service DLL will be load once and remain in memory until all files have been processed. By using some minimal communication between services we're going to significantly reduce the need to communicate with the scheduler after the initial processes are crated to attach the list of files to be decompressed.
I'm currently working on the new sample and will post it as soon as it becomes available.
No comments:
Post a Comment